Lockfree Atomic Queues with CAS
In numerous scenarios in computer science speed is very important. Conventional applications and programming makes use of single threaded programming where instructions are executed one after the other, in a sequential manner, but one drawback with this system is that all instructions are not immediate, often there’s wait time involved like waiting for input, waiting for an algorithm to execute or waiting on operating system resources to become available. What this approach implies is that independent instructions which are free from the outcome of the waiting instructions also have to wait, this leads to more time consumption increasing the execution time.
Threads can solve this problem, where a group of independent instructions could be executed in parallel thus saving time. C and C++ offer threads in pthread.h and std::thread class for the same. Multithreading leads to several race conditions where multiple threads consume and manipulate data/memory which is shared by all of them. If these access and modify operations are not synchronized it can lead to data corruption and undefined behavior. Classically this synchronization is performed with the help of locks and mutexes, where each competing thread has to acquire the lock on the shared resource before using it and than release the lock after that, this ensures atomicity and all the threads can use the resource without corrupting data. However acquiring and releasing locks is time-consuming and this can lead to severe performance penalties in high performance producer-consumer scenarios. So whats the solution ?
Lockfree datastructures !
Enter CAS …
CAS stands for compare_and_swap.
CAS is a CPU instruction, special hardware instructions are used to activate atomic hardware in the CPU. For eg. in x86 LOCK_CMPXCHG. The only operations that can be truly atomic are bare CPU instructions.
CAS has the following pseudocode :
CAS(var1, expected_val, desired_val) {
if (var1 == expected_val) {
var1 = desired_val;
return true;
}
return false;
}This whole operation is performed atomically. Languages like C/C++ have functions which provide this atomic operation in the form of functions. In C we have –
__sync_val_compare_and_swap()
__sync_bool_compare_and_swap()And in C++ its provided by std::atomic
std::atomic<T>::compare_exchange_weak()
std::atomic<T>::compare_exchange_strong()std::atomic<T>::compare_exchange_weak :
If the object invoking this function is equal to expected value, desired value is written into the object, else expected value is updated with the value of the invoking object. Is allowed to fail spuriously, i.e. acting as if var1 != expected even though they are equal. It’s preferred that compare_exchange_weak is used in a loop Used when object representation of T includes padding-bits, trap-bits, multiple representations for the same value.
std::atomic<T>::compare_exchange_strong :
compare_exchange_strong doesn’t require a loop Is used for objects with certain and fixed bit representations.
Atomicity in machine code
These functions are implemented in machine code using a special instruction prefix lock. The lock prefix ensures that the CPU has exclusive ownership of the appropriate cache line for the duration of the operation, and provides certain additional ordering guarantees. This prefix ensures the atomicity of the instruction. This makes sure that any other concurrent operation on the same memory address gets sequenced at the hardware layer.
Given below are x86 machine instructions for C++ code that performs atomic operations.
1. Atomic Increment
#include <iostream>
#include <atomic>
int main(){
std::atomic<int> i;
i++;
return 0;
}translates to :
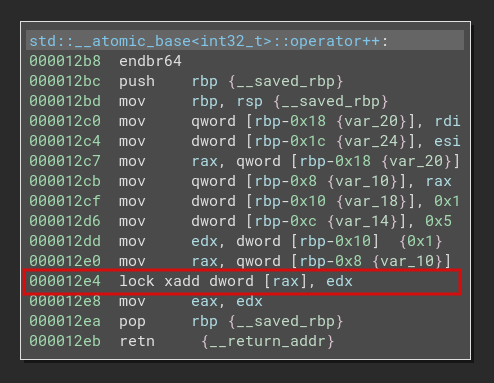
2. Atomic Compare and Exchange
#include <iostream>
#include <atomic>
int main(){
std::atomic<int> a(23);
int b = 23;
std::cout << a << std::endl;
a.compare_exchange_weak(b, 12);
std::cout << a << std::endl;
return 0;
}translates to :
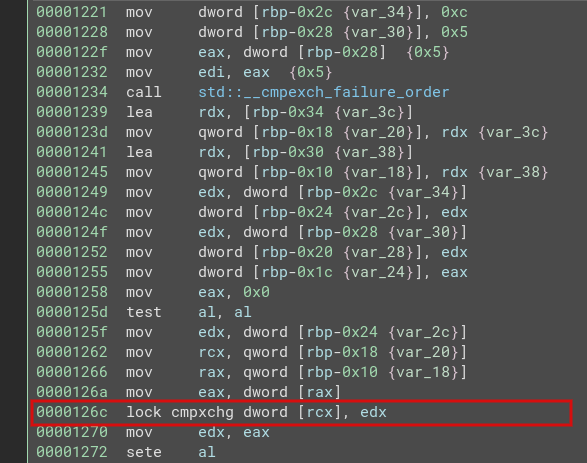
Let’s see how we can use these functions to implement a lockfree queue :
The lockfree Queue :
We will be using std::atomic types for data members because std::atomic prevents data races i.e. multiple threads trying to do a read-modify-write operation simultaneously on a same memory location, std::atomic prevents this interleaving of instructions, because each read-modify-write operation is performed atomically. lock is used to implement all the operators supported by std::atomic.
Implementation :
#include <iostream>
#include <atomic>
#include <thread>
#define MAX_ENQUEUE 1000
struct data_node {
int index;
data_node(int const& indx) : index(indx)
{}
};
class lock_free_queue {
public :
std::atomic<int> num_elements;
private:
struct node
{
data_node* data;
std::atomic<node*> next;
node(data_node* data_):
data(data_), next(nullptr)
{}
};
std::atomic<node*> head;
std::atomic<node*> tail;
public:
lock_free_queue() {
this->head = nullptr;
this->tail = nullptr;
this->num_elements = 0;
this->head = new node(new data_node(INT32_MAX));
this->tail = this->head.load();
// std::cout << " Created lock-free queue" << std::endl;
// std::cout << "HEAD : " << head << std::endl;
// std::cout << "TAIL : " << tail << std::endl;
}
void push( data_node* dta) {
std::atomic<node*> const new_node = new node(dta);
node* old_tail = tail.load();
while(!tail.compare_exchange_weak(old_tail, new_node));
num_elements++;
old_tail->next = new_node.load();
}
data_node* pop(){
node* old_head = head.load();
/*
* lock cmpxchg operation decides which thread gets to pop
* the head, and return the element.
*
*/
while (old_head && !head.compare_exchange_weak(old_head, old_head->next));
num_elements--;
return old_head ? old_head->data : nullptr;
}
void walk_queue() {
// std::cout << num_elements << std::endl;
node* node_ptr = head.load();
while(node_ptr) {
std::cout << node_ptr->data->index << " " ;
node_ptr = node_ptr->next;
}
std::cout << std::endl;
}
};
lock_free_queue lq ;
void* worker_push(void) {
data_node *iptr = nullptr;
for (int i = 0; i<MAX_ENQUEUE; i++){
iptr = new data_node(i);
// std::cout << iptr << " " << std::endl;
lq.push(iptr);
}
}
std::atomic<int> pop_count = 0;
void* worker_pop() {
data_node *iptr = nullptr;
for (int i = 0; i<MAX_ENQUEUE; i++){
iptr = lq.pop();
delete iptr;
pop_count++;
}
}
int main () {
std::thread t1(worker_push);
std::thread t2(worker_push);
t1.join();
t2.join();
std::cout<< "Num Elements after concurrent push :" << lq.num_elements << std::endl;
// lq.walk_queue();
std::thread pop_thread1(worker_pop);
std::thread pop_thread2(worker_pop);
pop_thread1.join();
pop_thread2.join();
std::cout << "Num Elements aftewr concurrent pop :" << lq.num_elements << std::endl;
// lq.walk_queue();
std::cout << "Elements after concurrent pop :";
lq.walk_queue();
}Explanation :
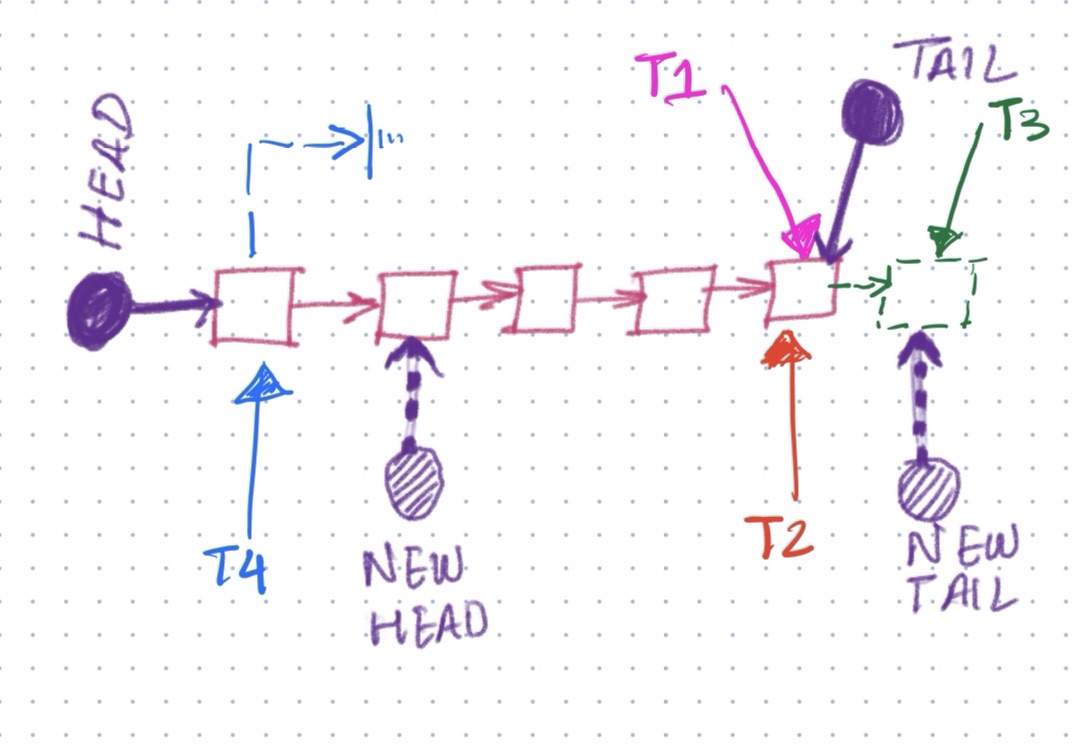
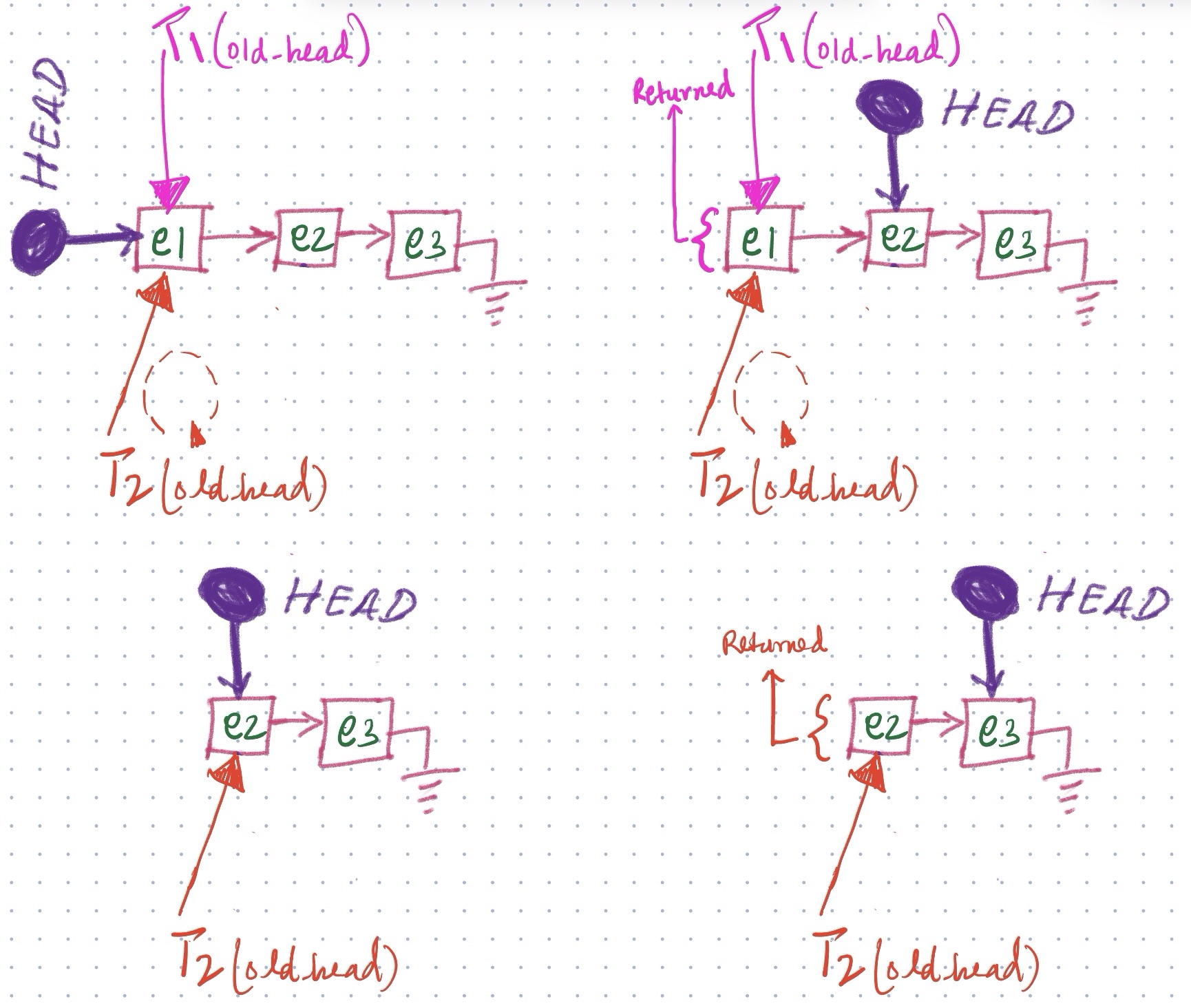
- Concurrent Push Operation : Let’s consider two threads T1 and T2 trying to simultaneously enqueue an element on to the lockfree queue. Insertions on the queue all occur at the Tail of the queue, as queues are a FIFO structure. Both the the threads T1 AND T2 store a pointer to the tail in a local variable old_tail on line:41. On line 42 both the threads T1 and T2 try to execute compare_exchange_weak operation on the tail with their respective new nodes. Due to the atomic and thread-safe nature of the function only one of them succeeds and updates the tail pointer to point to the new node. Let’s assume this lucky thread is T1. T1 modifies the TAIL pointer to point to its new element, which immediately frees T2 to further enqueue its element at the modified tail. In the meantime T1 can finish linking up old_tail to the new node T1 enqueued. There is a moment when both T1 and T2 are constructing the linked-list simultaneously, making use of CAS to avoid conflicting access, and than working with their respective local variables to work on their respective conflict-free zones.
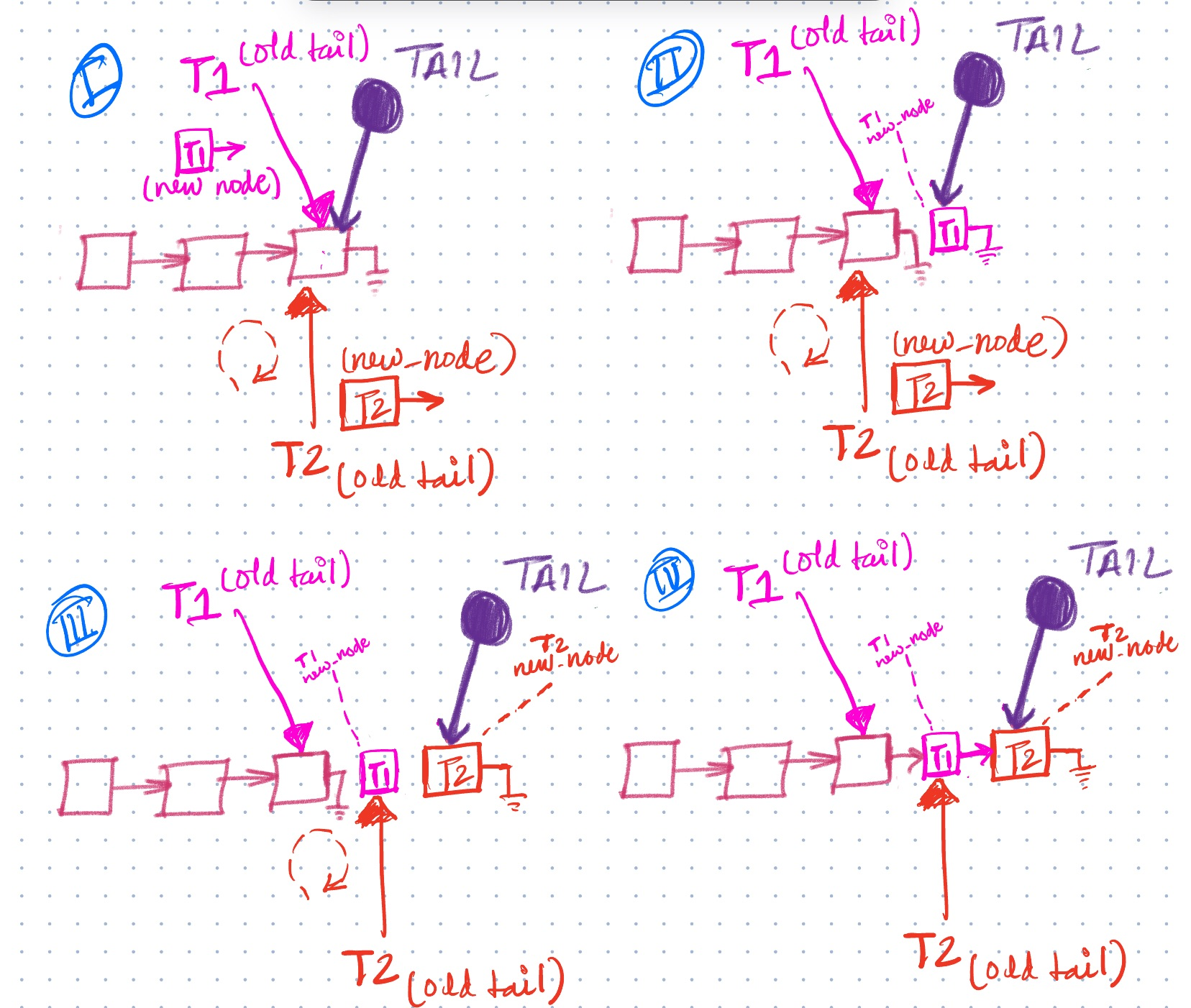
- Concurrent Pop Operation :
Let’s consider two threads T1 and T2 again trying to consume elements from the same queue, this dequeue operation will take place at the HEAD as its a FIFO structure. Both the threads T1 and T2 store the latest head pointer in a local variable old_head at line:48. If the queue is not empty i.e.
old_head != nullptrboth T1 and T2 try to performcmpxchgoperation on the head pointer, but because ofstd::atomicproperties we have thelockprefix which sequences the access to this memory location and only one thread gets to perform it. Lets in our case assume that the lucky thread is T1, T1 advances the head pointer on line:54 and returns the popped element. In the meantime T2 has been CASing in loop seeing that head no longer points to old_head on line:48 i.e. its been updated by another thread (possibly T1) hence failing to CAS and updating old_head to latest head. As soon as T1 updates the HEAD T2 immediately succeeds in CAS and advances the HEAD further and processes the popped element. T1 processes the popped element as T2 pops a new element from the queue, hence parallelizing the pop operation where both the threads work simultaneously.
Feel free to play around with the sample code in this blog, and explore many concurrency corner cases for this queue. The implementations used in production are more polished and memory managed. Hope the sample code helps making the concepts clear.
Lockfree Queues out in the Wild
The code provided above is just an example, any decent production level library implementations would take care of memory management using pre-allocated memory pools as memory allocation in itself is a locking operation. Some production level lockfree queue implementations could be found here :
- Boost.Lockfree – https://www.boost.org/doc/libs/1_72_0/doc/html/lockfree.html
- https://github.com/cameron314/concurrentqueue
- https://github.com/max0x7ba/atomic_queue
- https://github.com/rigtorp/MPMCQueue
- https://github.com/google-deepmind/mujoco/blob/main/src/thread/thread_queue.h
References
- https://stackoverflow.com/questions/25199838/understanding-stdatomiccompare-exchange-weak-in-c11
- https://en.cppreference.com/w/cpp/atomic/atomic/compare_exchange
- https://stackoverflow.com/questions/22339466/how-compare-and-swap-works
- https://jbseg.medium.com/lock-free-queues-e48de693654b
- https://www.schneems.com/2017/06/28/how-to-write-a-lock-free-queue/
- https://www.linkedin.com/pulse/inside-mind-c-atomics-mariam-el-shakafi/